


































































































































































































Chem Sci | NMRExtractor:利用大型语言模型从开源科学出版物中构建实验核磁共振(NMR)数据库
近日,中国科学院上海药物研究所郑明月团队开发了一种由大型语言模型驱动的NMR数据提取工具NMRExtractor,能够从海量开放获取的文献中自动提取实验性NMR数据,构建出了迄今为止规模最大的开放式NMR数据库——NMRBank。相关研究论文" NMRExtractor: leveraging large language models to construct an experimental NMR database from open-source scientific publications"于2025年5月28日在Chemical Science在线发表。

核磁共振(NMR)光谱是化学研究中强大且应用广泛的技术之一,NMR提供了关于分子环境的详细信息,这些信息对结构和原子间相互作用非常敏感。在过去二十年中,研究人员开发了多个数据库用于存储分子的1H和13C NMR光谱。例如HMDB、 NMRShiftDB2和NP-MRD,然而这些数据库的规模仍有限,最大的开放NMR数据库NMRShiftDB2仅包含53,954个实验测得的光谱,涵盖约44,909个分子。
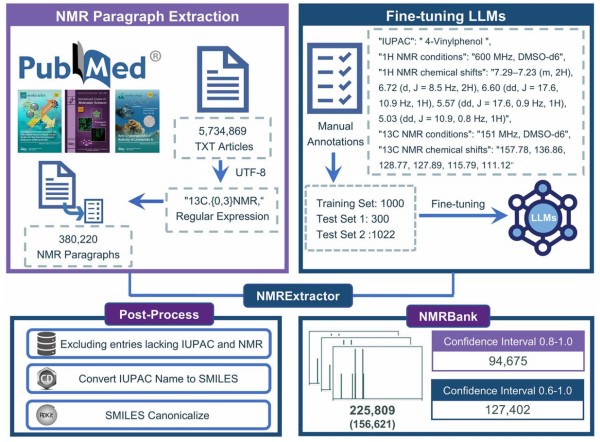
在这项工作中,研究团队提出了一种基于大型语言模型的高精度NMR数据提取工具——NMRExtractor,可自动从科学文献中提取包括化合物名称、NMR条件和1H/13C NMR化学位移在内的关键信息(图1)。通过该工具,研究团队从PubMed数据库中的570万余篇公开文献中批量提取NMR数据,构建了当前最大的开源实验NMR数据集NMRBank,其包含225,809条NMR数据记录,每条记录包括:化合物的IUPAC名称、SMILES描述符、1H/13C NMR化学位移、模型赋予的置信度评分,以及文章PMID和期刊名称等元数据。分析表明,NMRBank所覆盖的化学空间显著超越现有的公共NMR数据集。该提取流程具备高度可扩展性,支持新研究论文的自动处理,使NMRBank可持续更新。该方法不仅拓展了开放NMR数据的覆盖范围,也为基于人工智能的NMR预测及相关化学研究奠定了数据基础。
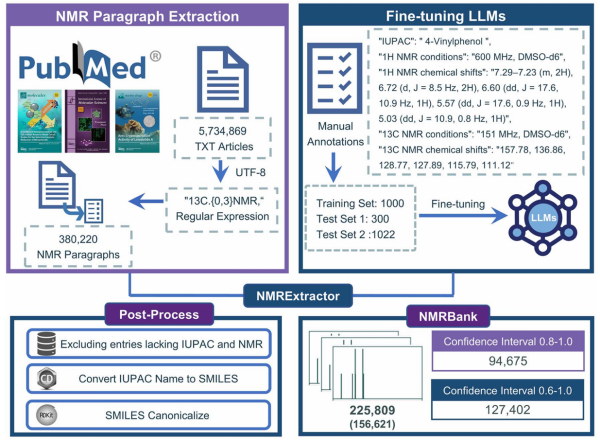
图1. NMRExtractor提取流程和NMRBank数据集构建的示意图
南京中医药大学与上海药物所联合培养硕士研究生王庆功、上海药物所博士研究生张玮为本文的共同第一作者。上海药物所郑明月研究员、博士后熊嘉诚、上海科技大学助理研究员付尊蕴为本文通讯作者。本研究得到了国家自然科学基金、国家重点研发计划、上海药物所与上海中医药大学中医药创新团队联合研究项目、上海市超级博士后计划、上海市市级科技重大专项等项目的资助。
原文链接:https://pubs.rsc.org/en/content/articlepdf/2025/SC/D4SC08802F